Steve, please let me know if this is something you would be interested in exploring. If not let me know and I will look elsewhere.
I think that Readlang is the best tool out there for reading at an advanced C level. If I know 98% of the words, that means I only have to look up 6-8 words per page and Readlang is the most efficient way to do it.
However, at an intermediate level, where I know much less than 98%, looking up every word is much less efficient. At a B level, I think reading and building up vocabulary with Interlinear texts is the best way.
I believe Readlang has the potential to become the best tool out there for the Intermediate level is well, if we use LLMs to create interlinear texts.
Moreover, I think that Readlang could totally change the language acquisition process.
I’m proposing two ways to do that. I’ve tested both of them with ChatGPT and they work. It’s just a matter of implementing them.
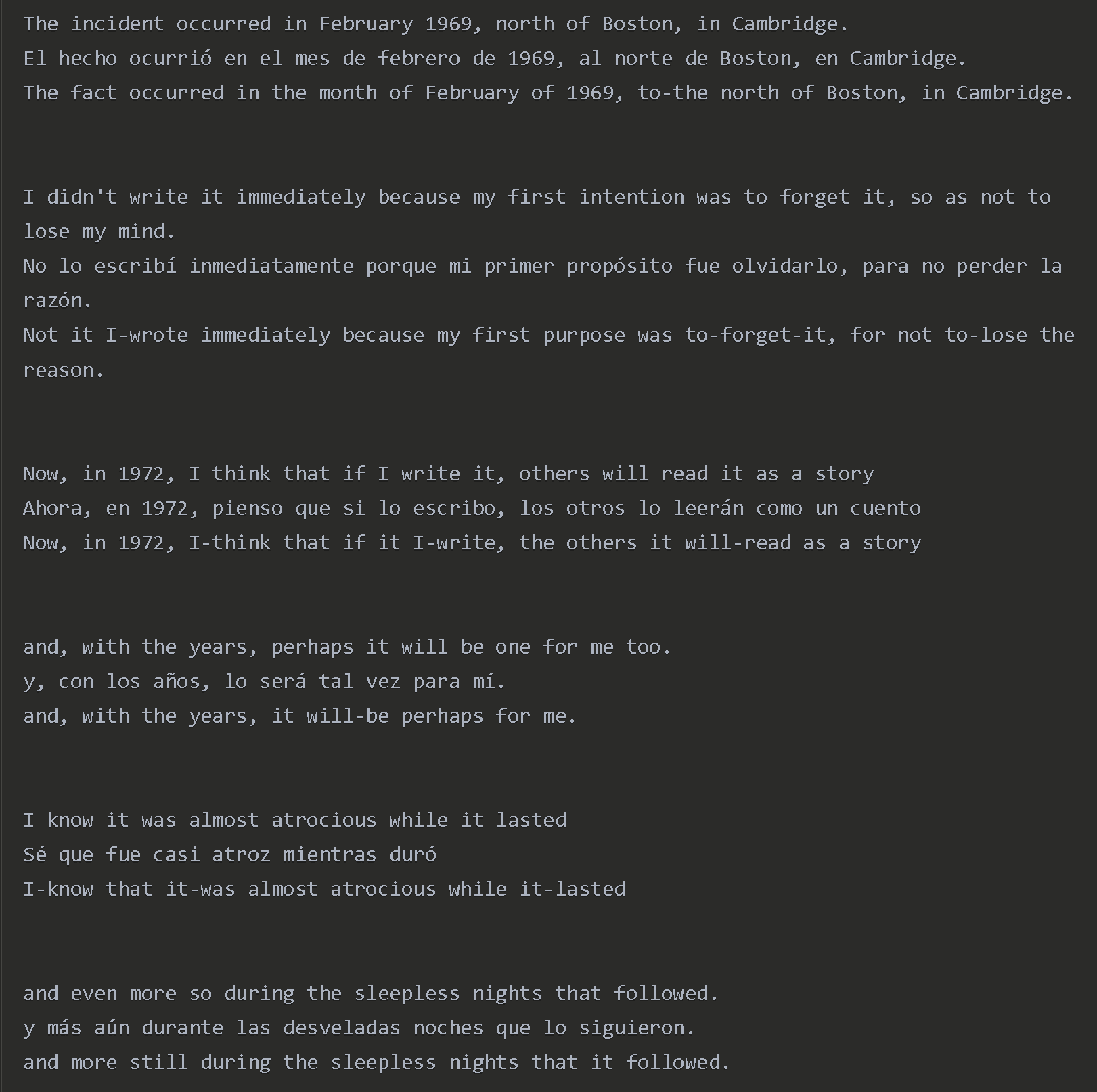
The first is to take a text (let’s say Spanish) in the target language and generate and thought for though translation, the best way to understand the text in the language one learns from (let’s say English). Then also generate a word for word translation keeping the same word order as the Spanish. At an beginner or intermediate level I don’t have enough vocabulary to figure out what’s going on my own. So, reading for comprehension is important, which is why I have the thought for though translation in the first row. So, I read a sentence or part of sentence in English, then I read the Spanish. Most of the time I can figure out the meaning and figure out which word is which. But sometimes there are idioms, and I can get the wrong understanding of the words. That’s when the word for word translation comes in. The word for word translation is there just for instances where thought for thought is confusing. I generate this text in ChatGPT and import it to Readlang. I occasionally look up individual words to check the chat GPT output, but for the most part it is good enough. At a beginner or intermediate level, this improves my reading speed significantly. After I acquire enough vocabulary, I can switch the order and have Spanish first and the two English translations after.
This could be easily implemented in Readlang. It would require implementing a prompt that would generate this text. This became possible with the o1 model. Any prior model couldn’t do it. So I’m doing this with the o1 mini. The actual translation is not perfect since the model is smaller, which is why I still use the Readlang translation occasionally. I can take an article in Spanish and read it at a decent speed even if I only know 25% of the words and acquire the rest of the vocabulary in the process. I can learn a language by reading. With just Readlang alone that takes just too long since I have to looking up so many words. In my prompt I broke up the text into sentences or smaller units so that it would display the three lines of text next to each other. That makes it easy to locate words. If the sentence is too long it would display two or more words of English, then two or more of Spanish, etc, which would slow me down. But the model is pretty good at splitting them up.
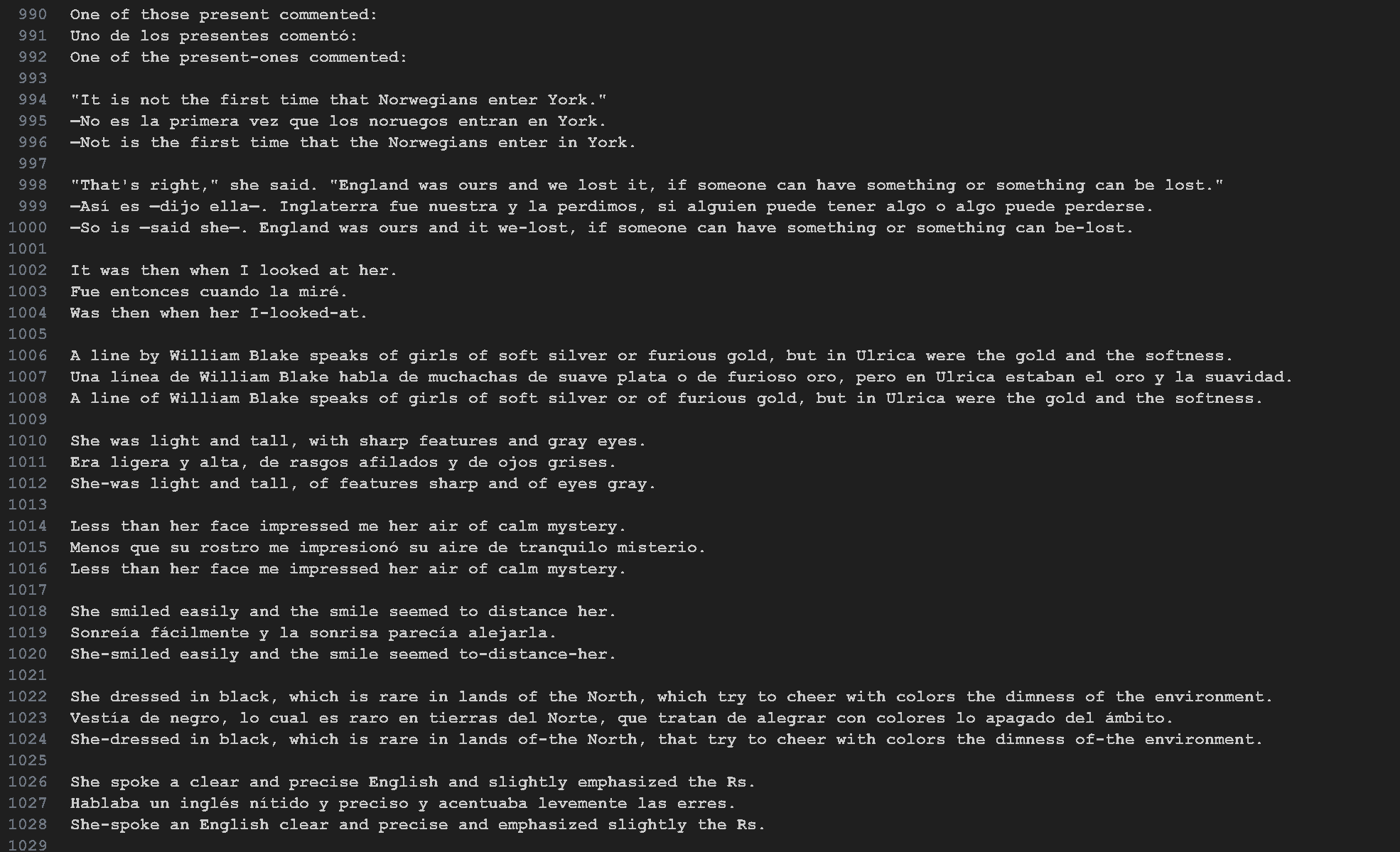
The second idea I believe is a revolutionary one and has the potential to change everything. At least it did change everything for me. The idea is to take two electronic translations of a book, let’s say a book in Spanish and its English translation and use a GenAI model to generate an interlinear text. Similar to the format above, I wrote a prompt to take the first sentence of the actual English text (with no alterations) or break the sentence up if it’s too large, then find the corresponding Spanish and place it in the second row. Then generate a word for word translation.
The advantage of this second method is that I’m using a human translation. I use the word for word machine translation mainly when the human translation takes liberties or when it translates idioms. I don’t read the machine translation. I use it occasionally when I’m struggling with the human translation. I still use Readlang to look up words in the dictionary or have the more advanced LLM explains words. But I’m mainly reading the human generated translation.
Sometimes two sentences in English are translated as one in Spanish and vice versa but I asked the model to keep that into account and it did. That’s why this could not be done before LLMs unless one did it manually. The two texts would get misaligned quickly. Also, this is only possible with the O1 or O1 mini model. Any other prior models would not finish the task no matter how many times I asked it to do it.
Why is this revolutionary? Because I can start reading more advanced books much earlier in the learning process. What are the alternatives at a beginner and intermediary levels? One is to look up 50-75% of the words with Readlang. That’s just not effecient. Another is to read two books side by side, but that is impractical as I have to switch my eyes left to right multiple times to find where I am in the text every time. Anyone who tried this knows it’s not very efficient. Another option is just read half a dozen manuals and all the interlinear texts out there 5-10 times until I internalize the vocabulary. Another option is to read with Readlang a little bit and then do flashcard until I internalize the vocabulary then read more and so on. All these options don’t seem appealing to me. I have not met anyone who LOVES flashcards. People do it because they believe it’s an efficient way to acquire vocabulary but even the most committed language learners see it as a chore. Personally, I don’t want to do flashcards, I want to read. So, my version of flashcards is to read a manual or interlinear text 5-10 times until I completely internalize the vocabulary. The downside is that this ignores the spaced repetition aspect and the fact that I memorize some words much faster, but the upside is that all the words are in context. Another downside is that I get bored of the text, unless it’s poetry. But how many interlinear poetry translations have you found out there? Poems are usually not translated word for word so It’s hard to acquire vocabulary that way. The only ones I could find are the Lieds published by Leyerle Publications. They published the complete songs of Schubert, Schuman, Brahms and Strauss. They give you phonetic in the first line, followed by German, then word for word English then thought for though English. Then a commentary at the end. It’s the best way to learn German poetry. They also published opera libretti, but that’s only for German, Italian and French. They have nothing in Spanish. And they are expensive, $100 per book. Reading fairytales 5-10 times in a row gets pretty boring quickly. It becomes a chore.
That’s why I believe that what we are going through right now is so revolutionary. I’m day 50 in my first Assimil manual in Spanish (still a beginner) and have no prior experience with the language. And I started reading the book Papyrus: The Invention of Books in the Ancient World by Irene Vallejo. This is text that has 20,000 unique words, so it’s a C2 text. I took the original Spanish and the English translation and generated the interlinear format as described. By reading the human translation first, I comprehend 100% of the content. Then I read the Spanish and I can mostly understand the Spanish, meaning I can make up which word is which. I occasionally rely on the word for word translation and every now and then use Readlang. I wasn’t planning to start reading in Spanish in my first year because it’s just too inefficient to look up most of the vocabulary. But I wanted to read this book in English so I thought, why not read it in Spanish as well while I’m reading in English. On the downside, it will take me 3 times longer to read, on the upside, I will acquire vocabulary in the process. And it works. I’m starting to internalize the high frequency words without even trying. I’m just reading.
The reason I believe that this is revolutionary is that for me, this is not studying. This is reading! It’s slow reading for sure, but reading, nonetheless. And significantly faster than looking up every word. It’s a book I want to read badly, I’m excited to read it. I love it. I can’t wait to get back to it. And that draws me to it. And I just read it in Spanish as well and acquire vocabulary in the process. This is an entirely different experience than doing flashcards or reading the same texts 5-10 times.
Another reason this is revolutionary is that you can basically take any two texts, in any two languages and read like this. You can take languages in which there’s not interlinear texts at all or not even good manuals. You can also get an audio book and shadow it and learn the sounds of the language like that. You can take a book that you find interesting. All interlinear texts are literary texts. But some people want to read Crime or Mystery or Fantasy novels, or History or Biography or Science or Academic books. Whatever you want, you can read it. When my Spanish is more advanced, I could take a book and generate a Portuguese, Spanish, English (all human translations) and English interlinear and learn Portuguese via Spanish. And improve my Spanish in the process as well. How many interlinear texts are there that have these three languages side by side? Zero! How about Dutch, German and English. Zero. How about French, Italian and English? How about Norwegian, Danish, German and English? The possibilities are endless.
Alexander Arguelles said many times that people want to read the great classics too soon. But you have to work your way up to it. Reading a literary masterpiece should be your goal but it will take time to get there. The reason he said that is that people lack the vocabulary to read at that level. And looking words up in the dictionary and through Readlang or reading with two books side by side is just not an efficient way to read. He said that because these texts are not available in interlinear formats. But now they can be.
But the most important reason this is revolutionary is that it collapses the goal and the process. The reason I (and many other people) want to learn languages is to read in them. But why wait such a long time, why “study” so long and so hard, why struggle with flashcards? Why not just read?!? We can both read and acquire the language at the same time. If the motivation for learning languages is to read, why not use that motivation to drive the entire process, to drive the language acquisition?
This concept is not new. This is the Hamiltonian method. What’s new is technology. Someone had to create this by hand, which is why we have so few interlinear. Now you can pick any texts, the text you want to read right now, and just read it. Whatever grabs you. And because you are reading and not studying flashcards, you will do more of it, and because you will do more of it, you will acquire vocabulary faster. The reward for doing it this way is to get faster at it by internalizing more words, which would allow you to read more.
The technical challenge is that I still have to do it manually in ChatGPT and I can only do it 7000 words at a time via the chat because it limits the text input. The o1 mini model could process about 15,000 words at a time like this through the API, but I don’t have the skill to do it on the back end.
The ideal solution would be to upload the epub files for the two books then have a script in the back end that would break those texts up to a manageable size, run the prompt, then put them back together. This could be done.
A simpler way is to just build into Readlang upload a way to upload multiple texts and then display them and generate the interlinear text. Let’s say upload text 1, then text 1 (and even text 3 as optional) then display text 1 in the first row, text 2 in the second roe and the word for word LLM generated translation in the row of your choice. Maybe have a menu to select the order. And then build a prompt to run this. This would be super easy to implement. It would take a bit more time because we would have to break up the text manually, but we could have this as a temporary solution until we can figure out a solution to handle a whole book. I’m sure the context window for the models will keep expanding so maybe it will be able to handle more soon, but that would be more expensive too. So ideally, we would have a solution to break them up and run them with the cheaper models.
The compute for this can get expensive. I don’t have exact numbers but maybe using the o1 mini to handle a 450 page book like this would cost around $15 dollar. Not cheap, but totally worth it. If you want to buy a book in this format from DoppelText (without the word for word) it will cost you $10-20 dollars. So the cost is comparable. We would probably want to build an API for this or sell credits for the compute.
Most people give up a language at the beginner stage. From those who persist, most give up at an intermediary stage. Very few people get to an advanced stage. Very few people acquire a vocabulary of 20,000 words to be able to read at an advanced level. I believe this has the potential to change everything because it allows people to get to the reward faster and acquire the language through reading what grabs them, whatever that is. They can get the basics by going through a manual 10 times and just start reading like this and in time acquire the language. And since the process is enjoyable they will be much more likely to stick with it.
Here are the two prompts that I wrote to do this. I keep tweaking them so they will likely evolve but they get the job done.
Here’s the prompt to take a text in Spanish and translate it:
For this chat you are a translator and creator of interlinear texts, like those published by Leyerle Publications. The purpose is to help me learn a language by providing a thought for though and a word for word translation. I will give you a text in a language other than English.
Take the 1st sentence of the text I have you. If the sentence has more than 15 words, split it so that each row doesn’t have more than 15 words. When you split it, pay attention to the meaning and make sure that the split is in a place where there is a natural pause, like after a comma or conjunction.
In the first row I want you to create an interlinear text by translating the text though for though into English so that the text can be understood in English. Place this translated thought for thought text in the first row.
In the second row reproduce the original text exactly.
In the third row, translate the original text word for word. Each word must always be translated in context. The meaning of each translated word must always coresponed to the meaning of the word used in that context. The order of the translation must always be exactly the same as the origianl even if it doesn’t wound good in english. Do not add any dashes between words. The purpose of this translation is to easily identify what the words in the original mean.
Then add a blank row. The height of the blank row must always be double the height of text rows.
Then take the 2nd sentence from the text I gave you, or if the 1st sentence has be split, the next part of that sentence, and continue the steps presented above for the entire text.
The output must be a text split by sentence or part of sentence and each sentence or part of sentence must always have three lines: a thought translation in the first row, the exact original reproduction of the text I gave you in the second row and a word for word translation keeping the exact word order of the text I gave you in the third row. The order of the rows must always be the same.
It is absolutely critical that you follow these instructions exactly and that you do not alter the text I give you. The text I give you should be 100% exactly the same in the output text. And the order should always be the same, original English first and then your word for word translation.
Also, always pay attention to the meaning. For example, if you see a row with a special character like a dash (-) or some other special character or number, that doesn’t count as an English row and must be skipped.
Display the output text in a plaintext box in the entirety. Do not stop untill the entire text has been displayed!
Here’s the prompt to take two translation and generate an interlinear texts with them:
I will give you two texts. One in English and another one in another language (Spanish, German). I want you to create an interlinear text by breaking the english text up sentence by sentence and after each sentence paste the corespending sentence from the the other language without altering either text.
Take the 1st sentence in the 1st row from the English text I gave you. If the sentence has more than 15 words, split it so that each row doesn’t have more than 15 words. When you split it, pay attention to the meaning and make sure that the split is in a place where there is a natural pause, like after a comma or conjunction. Also, when you split the English sentence you have to make sure that you do it in a place where you can also split the Spanish sentence without loosing meaning.
If two sentences in English are translated into one sentence in Spanish, split the one in Spanish as well but make sure that the parts corespond to the two English ones. If one English sentence coresponds to two sentences in Spanish, split the English sentence but make sure that the parts corespond to the two in Spanish. You need to match the meaning of the Spanish words to the meaning of the English words without altering the words or their order in any way. The only thing you do is split them.
Also, always pay attention to the meaning. For example, if you see a row with a special character like a dash (-) or some other non-word character, that doesn’t count as an English row and must be skipped. The first English row in every triplet should always be a sentence with meaningful English words.
For example, if I give you an English and a Spanish text, in the 1st row take the first English sentence exactly word for word, unless it has more than 15 words, in which case split it at an appropriate place to not break off the meaning. Also, when you split the English sentence you have to make sure that you do it in a place where you can also split the Spanish sentence without loosing meaning.
Then in the 2nd separate row take the coresponding sentence from the Spanish text exactly word for word and paste it after the English sentence. If the English sencence has been split, you will have to split the Spanish sentence, but the the Spanish sentence will have to contain the same meaning as the English sentence.
Then in the 3rd separate row create an interlinear translation by translating the Spanish text word for word into English. Follow exactly the same word order as the Spanish even if it is unnatural in English. For example “pared blanca” must be translated as “wall white”, “gente peligrosa” must be translated as “people dangerous” and “forasteros armados” must be translated to “strangers armed” to allign 100% with the Spanish word order.
Then add a blank row. The height of the blank row should be double the height of text rows.
in the 4th row take the next English sentence exactly word for word or the next part of the first sentence if it was broken off, unless it has more than 15 words, in which case split it at an appropriate place to not break off the meaning. Also, when you split the English sentence you have to make sure that you do it in a place where you can also split the Spanish sentence without loosing meaning.
Then in the 5th separate row take the coresponding sentence from the Spanish text exactly word for word and paste it after the English sentence. If the English sencence has been split, you will have to split the Spanish sentence, but the the Spanish sentence will have to contain the same meaning as the English sentence.
Then in the 6th separate row create an interlinear translation by translating the Spanish text word for word into English. Follow exactly the same word order as the Spanish even if it is unnatural in English. For example “pared blanca” should be translated as “wall white” not as “white wall” to preserve the Spanish word order.
Do this for the entire text. Do not stop untill the entire text has been parsed like this.
The output should have the exact English text that I gave you in the first line, the exact Spanish text I gave you in the second line and the word for word translation that you generated in the third line. There should be three separate output rows for each sentence.
It is absolutely critical that you follow these instructions exactly and that you do not alter the two texts I give you. The texts I give you should be 100% exactly the same in the output text. And the order of the lines should always be the same, original English first, original Spanish second and then your word for word English translation of the Spanish text third.
Display the output text in a plaintext box in the entirety. Do not stop untill the entire text has been displayed!