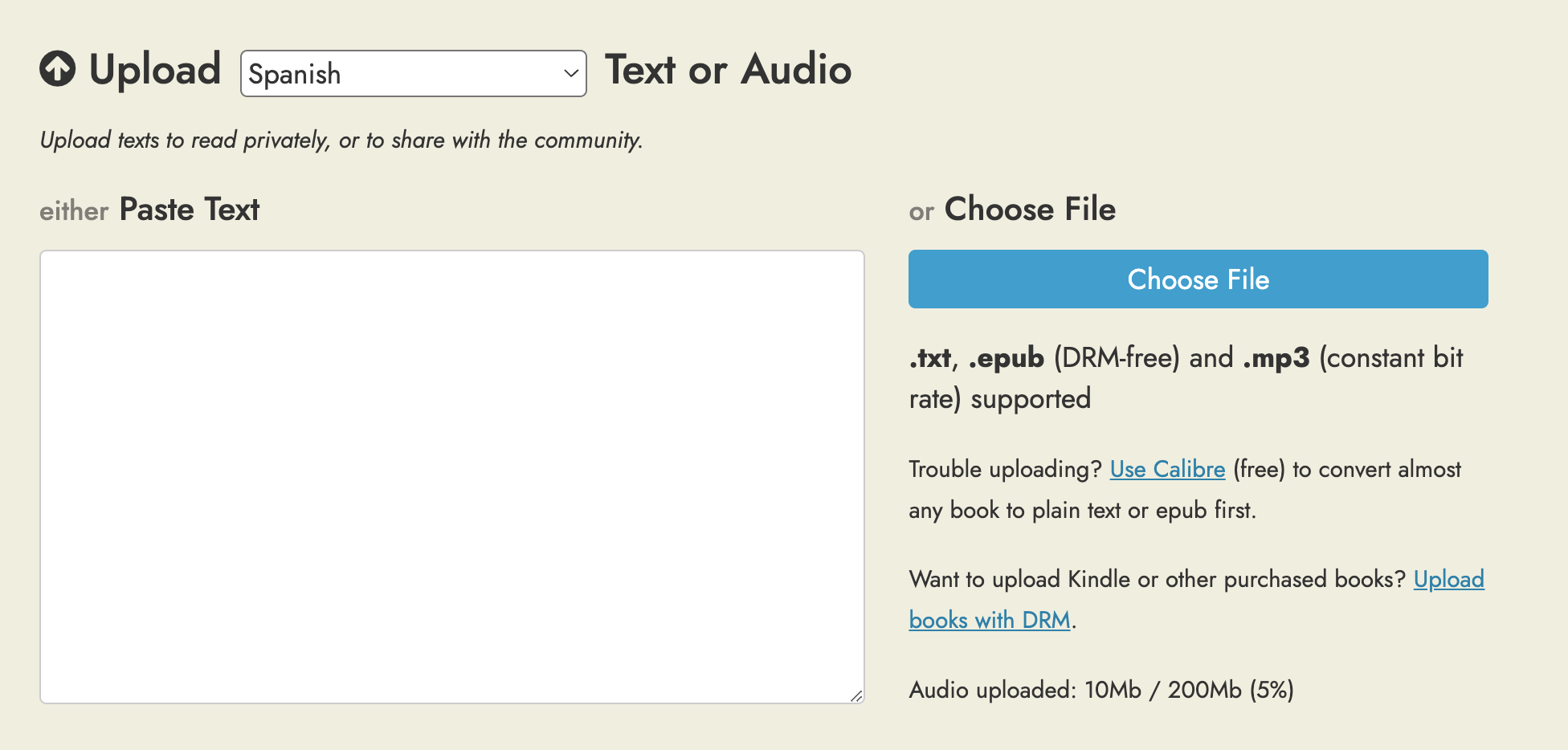
I’ve had a lot of requests for this over the years, and I’ve finally gotten around to adding it!
You can now upload mp3 files to Readlang.
For now this is an experimental feature in beta mode available to premium subscribers only. You’ll need to enable it at the bottom of the Settings page:
You can play/pause the audio using the button at the bottom of the reader page, just like for the Read Aloud feature.
In addition, there are 3 new keyboard shortcuts inspired by YouTube which work both with uploaded mp3 files and with the TTS (text-to-speech) based Read Aloud feature:
j: skip back 10s (mp3) or 8 words (TTS)
k: play/pause
l: skip forwards 10s (mp3) or 8 words (TTS)
Limits:
Only 20Mb per file (this is due to a limit with the OpenAI API, you could consider using a program like Audacity to split audio files into multiple files and/or convert to mono and reduce the bitrate slightly to squeeze more out of this file size limit)
Only 200Mb total audio files per user
You can’t tweak the transcript yourself afterwards without potentially messing up the synchronization. (I can work on improving this, but right now I’d advise against editing these, apart from possibly adding paragraph breaks - that should be safe)
Very likely that for certain languages it’s not going to work so well due to the limitations of the OpenAI whisper model
Very likely that there are bugs due to my code
In general, it seems to work pretty well in Spanish and French. Some issues I’ve noticed:
Some speech is missing from the transcript. In a podcast where a woman and man were talking the man’s voice was only transcribed some of the time
There are no paragraph breaks. So it’s a big wall of text, and there’s no indication in the transcript when the speaker changes.
Please try it out and let me know how it goes. Particularly interested in bug reports.
Incredible! This is a big feature! Was wondering if there is also a time limit on the audio? I understand that it has to be 20mb or under but does the length of the audio matter? Thanks Steve
There’s no time limit per audio file at the moment, just whatever you can squeeze within 20MB.
If you encode your mp3 in mono, 44KHz, 56kbs, which still sounds pretty high quality, then you can fit 48mins worth of audio within a 20Mb file. If you go more aggressive and use mono, 32KHz, 32kbps you could squeeze 85mins within a single file, and the audio quality should still be OK. I wouldn’t want to go lower than that though, and in fact when it comes to calculating storage I’d be tempted to make files under 32kbps count as if they were 32kbps to avoid encouraging people to get too aggressive and make bad sounding audio, and because OpenAI actually charge per minute of audio for transcribing, not per MB.
Hey there Steve, awesome work on this feature and many thanks for implementing it, and in particular replying to my post from last month about it, I likely wouldn’t have known if not for that notification.
This feature is really cool and the synch works great, but there are two things to perhaps consider in future (if the latter one is actually possible, of course);
It would be very nice if users who have their own native transcripts could simply upload audio and have it as a simple player that they listen to while reading themselves without synch (since I assume it would be hard or impossible to auto-synch these two separate sources).
Not a big deal for people with some experience in the language who can mentally replace wrong words in the transcription, but for newer learners this may be an issue; I don’t see a way to edit the transcript (even by one character) without the audio being automatically removed from the page. If possible to fix this would be ideal as, for my example in Arabic, Whisper seems to struggle sometimes telling the difference between ا and ع.
Just one last bit of appreciation, I’m sure you’ve worked very hard on delivering this and it’s amazing, puts this platform ahead of the competition by far in my opinion especially when it comes to the smooth user experience compared to others.
Yes, your vocab will remain untouched, and any context sentences you have attached to vocab will remain, but the source (including the title of the text) will be lost.
There isn’t right now, but this would make sense and I’ll probably add that before this feature graduates from beta mode.
Just want to say that this is awesome and thanks for adding this feature! I am eagerly awaiting the transcript auto-sync feature! I’m noticing that when I do submit mp3s that the service ends up treating it as a wall of text. Not a deal breaker but it would be a big quality of life improvement to be able to format the text while still having the audio sync correctly.
Update: you can now edit the text of the auto-generated audio file transcript, or completely replace it with a better version, and it will do its best to keep the sync points intact.
(For the technical among you, it uses a diff algorithm, a bit like you’d use to compare two versions of a source code file, but on a word-by-word basis instead of line-by-line.)
Please let me know if you come across any problems when using this!
With some media, I struggle slightly to decide whether to use this or to sync a transcription with a YouTube video. My initial instinct was that this and the YouTube feature overlap a lot and should probably be one feature; I’m less sure about that now I’ve used it a bit more.
Here’s a specific example to illustrate what I mean. I listen to the InnerFrench podcast. Let’s take this episode as an example: #02 Vivre avec des robots - innerFrench
The YouTube method
Method
Advantages
Disadvantages
This is what I used to do before you released the MP3 upload feature:
Copy the transcript from the episode page and add it to Readlang.
Grab the YouTube video URL (this is just the podcast audio, but on YouTube) and add that to the transcript, then read/listen in Readlang.
The transcript is produced by the creator, so I’m pretty confident it’s accurate.
No limits on how many of these I can store, as the media isn’t being uploaded to Readlang.
I have to sync the YouTube video to the transcript. Although this feature works really well, I find it a bit distracting on the first pass through; I’m concentraing more on whether the transcript is in sync than on what’s being said.
The MP3 method
Method
Advantages
Disadvantages
Download the MP3 from the episode page and upload to Readlang.
Easier. Readlang handles pretty much everything.
No need to sync the audio to the transcript, so I can focus on reading.
I can’t used the transcript provided by the creator. Although the auto-generated transcripts seem great so far, I’d feel more confident using an official one if available. Side note: This might be solved now that you’ve made transcripts editable. Maybe I can just replace the auto-generated transcript with the official one and (assuming they’re largely the same) your diffing process will keep it in sync?
Can take slightly longer if I have to compress the audio to get it under 20MB.
I’m conscious that I’ll fairly quickly hit the storage limit and will need to start removing older media (haven’t checked yet if I can just detach the audio file, or if I need to delete the whole transcript to free up space).
When I mention merging the two features (again, not sure that’s actually the right solution), I think syncing is the main feature that could be shared between them. Either transcribe YouTube videos so that Readlang can automatically sync with the transcript (appreciate this would add a lot of cost on your side, so might need to be in a higher tier of subscription), or continue to evolve the MP3 upload so that the syncing is more editable. It feels like we’re halfway to that now with editable transcripts. It would be interesting to see if the manual sync feature from YouTube videos could be applied to the MP3 feature as well.
From this, the timings could be extracted which I could then align with a better quality transcript if you can provide that. The timings aren’t on every word so not as good as on the audio upload, but it’s probably good enough, and you could always tweak it later if you like.
Another possibility is to try to extract the audio from the YouTube video and then use the OpenAI whisper model just like I do now for the mp3 uploads to generate the sync points.
Both of the above methods have the downside that anything I implement now may not even be supported by YouTube’s terms of service and even if they work now could easily be broken if YouTube changes. Option (1) is the one I’m more likely to try. Removing this dependency on YouTube is one of the main advantages of the new mp3 upload.
This should now be solved! You can just replace the auto-generated transcript with the official one. Please give it a try and I’d love to get your feedback on how well it works.
Yeah, this is a bit annoying. The reason for this is the 25MB limit of the OpenAI whisper API (in my testing I was hitting the limit even under 25MB which is why I set it to 20MB). I’m considering an option which lets you upload a larger file and automatically compress the audio to something reasonable for spoken word, say 64kpbs mono (about 42 minutes). I might even just automatically compress all uploaded audio to a standard bitrate and then the limit would be in minutes and seconds instead of filesize, which would be easier for non-technical people to understand I think. Maybe with standard quality (64kbps mono) or high quality (128kbps stereo) options.
My tentative plan is that the normal Premium plan will have 100MB (about 3.5 hours at 64kbps) and that the more expensive Premium Plus plan (pricing page) will have 2GB (about 70 hours at 64kbps, or 35 hours at 128kbps).
This is possible, but I’m hoping that it’s not necessary since the process is a bit fiddly. If I get feedback and example audio files from people demonstrating cases of the automatic synchronization not working well, I’ll consider it at that point.
That sounds like an interesting idea. Agree that trying to extract the YouTube audio is probably a bit prone to breaking/against their terms of use. Syncing up a subtitle track seems like a more robust solution. I’ve been playing around with asbplayer recently for YouTube and Netflix videos, and it seems to extract the subtitle track pretty easily, and you can then export it from the asbplayer extension as an SRT file. I haven’t dug into their code, but it may be an interesting example to look at to see how they’re handling it.
I’ve tested this with a few audio files and it seems to be working perfectly! This workflow is really simple and gives great results. I’ve now got original audio and creator-provided transcripts perfectly in sync.
That sounds like a good approach. I’m a software developer and we’re using the whisper API for some basic transcription at work. We’re getting around the size limits by automatically splitting the audio into 20MB chunks (just using ffmpeg on the server), sending them to the API separately, and then stitching the transcripts back together. That works for us because we know the input audio is always encoded at the same bitrate, but I guess for user-uploadable content, reencoding to ensure consistency is a better approach.
Understood, and I agree it’d be good to keep it simple.
One other feature from the YouTube integration that would be really nice if it could be added to the audio player: having an option to click a word and the recording starts playing from there. I use that a lot with YouTube videos and would love to be able to do it for audio as well. Also related to this, I was reading/listening to something in Readwise on my phone the other day and realised that without an external keyboard, I don’t think there’s a way to skip back and forth in the audio? Appreciate you probably don’t want the interface to get too cluttered, but some back/forward buttons would be much appreciated!
This feature is really useful and the ability to upload podcasts was one of the main reasons I’ve been using Lingq more lately.
I find the file limit on this implementation is really holding it back as 20 mb is too small for most of the podcasts I have. I think Lingq does 120 mb (dont quote me on that) Probably using some kind of compression to get around whisper’s cap?
There’s now a way to add timings from YouTube videos: Easier way to sync YouTube videos (beta). Still a bit fiddly but hopefully an improvement vs doing it all manually.
Agree. I’ll work on something here. Recompressing for the purposes of transcription seems a promising route to get up to a couple of hours worth of audio at least.
I just tested this and it works brilliantly! As you say, a tiny bit fiddly to do all the steps to import everything, but overall infinitely quicker and easier than trying to sync it manually.
Here’s my test if it’s helpful. The speaker switches to English a few times, most of which isn’t in the transcript, but it seems to cope well with that and just waits until the French resumes for the highlight to continue moving.
Big update – you can now upload far larger audio files!
Here are the changes:
individual mp3 audio files up to 200MB and 2 hours in length are supported
audio is re-encoded to CBR (constant bit rate) for playback in browsers to avoid sync issues, the quality depends on your subscription plan:
Premium users get mono 64kbps (good quality for spoken voice audio)
Premium Plus users can choose stereo 128kbps (excellent quality for spoken voice audio, also decent for music)
audio storage allowance is now measured in hours of audio instead of file size:
Premium users get 5 hours
Premium Plus users get 100 hours
Please give it a try (enable audioUpload here and upload audio here) and let me know how it goes! (still in beta while I collect feedback, fix bugs, and polish some rough edges)
Hi. Regarding the wall of text. I find that Readlang’s own sentence break feature makes a huge difference. Unlike YouTube’s automatic transcriptions, Readlang’s MP3 transcriptions are at least separated into sentences. With Readlang’s feature you can start each sentence on a new line. Not as perfect as splitting into paragraphs perhaps, but it’s instant, saves a lot of time, and suits me fine.
It’s on the AA tab, under change appearance, “Sentence breaks” (default being “No sentence breaks”).