This feature is in beta and is not linked to from anywhere within the app yet. Your words will need to be in the correct CSV format as described at the above link so it’s targeted at the more tech-savvy for now!
Please reply with feedback to let me know if it’s working for you or not.
Thank you very much for the amazing feature and for your support. It is working exceptionally well for me at the moment.
PDF :
Readlang wordlist :
The translation was generated by GPT. This helps me avoid the annoyance of using Google Translate API (I suggested this before) and assists me in reading PDFs.
That wasn’t intentional! I’ve fixed it now so it’s case insensitive. Also, I’ve added a text input below the file input so you can paste your CSV data instead if you prefer that.
Not important: Is it possible to import text containing the ’ / ’ sequence of characters without it being treated as synonyms?
More important: I’d feel safer if importing this would not lead to the creation of two new flashcards, but one flashcard with just 2 translations (hopefully not 4) and 2 contexts:
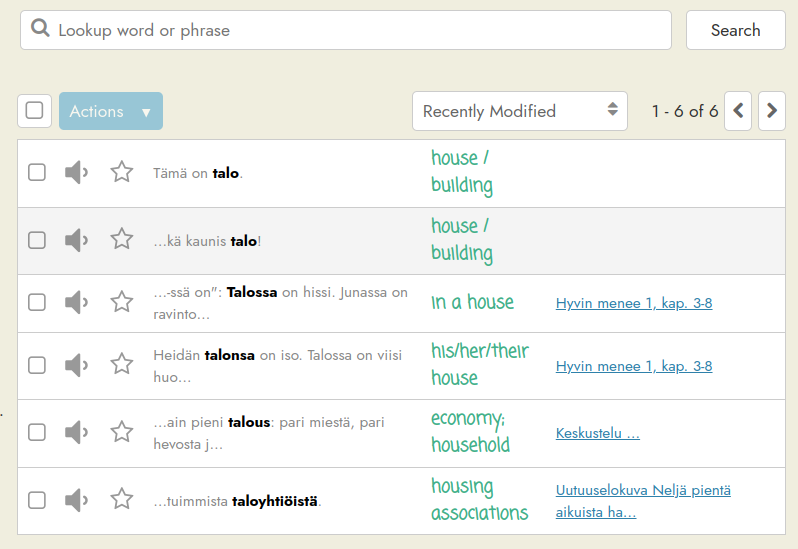
talo,house / building,Mikä kaunis talo!
talo,house / building,Tämä on talo.
At the moment this isn’t possible. I could make it so that if you inserted a double // it would convert it to a single / character instead of treating them as synonyms or alternate translations.
This is how it’s meant to work. It should merge them to create one flashcard with 2 translations and 2 contexts. If it doesn’t, please let me know!
I exported 100 words from Language Reactor. The CSV has a lot of fields not needed here so deleted those columns. Their format required a few search and replace operations to remove commas and insert slashes.
LR exported the context as multi-line strings. Because of the additional helpful context, I tried using that column first. The RL import just hung with the progress wheel stuck in place.
Substituting the one-liner context from LR, everything seems to have worked splendidly.
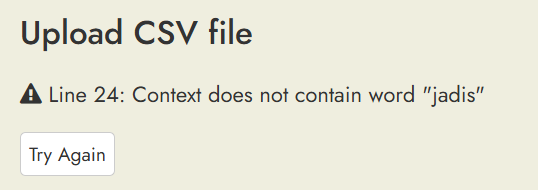
Thanks for reporting this. I’ve fixed it so that it will report problems with specific lines in the CSV input instead of hanging in a couple more cases. Please let me know if that hanging issue happens again for you.
I’ve also clarified that multi-line contexts are not supported on the import page.
I’ve fixed this now! Please let me know if you come across any further problems!
Hello. Thank you for the great extension! Is it possible that the presence or absence of the exact word in the context does not affect the file upload? There are some languages where the infinitive of a verb looks different from the verb used in the context sentence, therefore you can’t upload words or a file in CCV format if the word inside the context looks different from the separate word.
Sorry, but storing contexts which don’t contain the exact form of the word would break the way Readlang’s different practice modes work. The way Readlang handles languages like this is to store each different conjugation of the verb as a different flashcard.
That’s a pity. When I add a word in the regular way, in such cases I get a message saying that the context “supposedly” doesn’t include the word. I just ignore this message and still can upload both the word and the context. I thought it would function the same way with bulk upload.
I’m wondering what you plan to do with the words you’re importing, since the flashcards will not really work properly if the exact word doesn’t appear within the context.
Yes, I know that in this case the sentence with the word appears above the cards without the gap. But that doesn’t bother me. I just don’t look at that sentence before giving the answer. And only then do I look at the context to see exactly how the word acts in context. With a language like German, for example, it’s hard to manage any other way. Otherwise I would have to put the whole long sentence as the word to be reviewed, because in that language the verb is often divided into two parts and the prefix goes to the very end of the sentence.
when i export words there is source column, but when i try to import it doesn’t accept source column. i want to import some words and studding just these words. how can i study especially words which i imported.
I’m testing import and export, and I believe I found a bug in the export. I have 88 words in my library, but whenever I export all words, the exported file contains 92 words. A bunch of words have been duplicated.