Does anyone have any experience with this? When I try to use calibre to convert pdf to txt, the output file has a null length and calibre informs that the conversion has crashed…
What I do is Ctrl-A / Ctrl-C to copy all the text into MS Word. Then do a find replace on all paragraph break special chars…replacing them with a space. Then Ctrl-A / Ctrl-C all the text and paste into Readlang. Works pretty well for me.
Occasionally you may have to do some additional cleaning - for example if headers / footers are repeated but generally it’s very quick.
Thanks for your suggestion. This would work for short or incidental texts. However, I am often reading texts which are hundreds of pages long which would make this a very tedious and impracticable process.
If you are on Linux or Mac then you can use pdftotext via the commandline. I prefer it to Calibre since sometimes I get strange behavior with Calibre as you noted. On windows you can probably install it via WSL, not sure if there are native window binaries for it.
It probably doesn’t answer your query about longer PDFs (I can’t find a limit), but for those interested in re-formatting shorter PDFs, YouTube transcriptions, etc, I use TextFixer, a free online suite of text tools, that includes a line-break remover. I simply copy and paste the text into TextFixer, and from there into ReadLang:
Hello Steve, Is there any possibility to import PDF with picture? I have a lot of scientist text with I need to read and for their understanding I also need included picture. Please help.
Thank you for your response. Please consider it. There are many technical ebooks which contain pictures and charts. And your app with AI and dictionary can really help to learn technical terms.
I find calibre complicated and difficult to use, and I would ideally prefer to convert files from my iPad some times. Google Drive is so much easier. Just open drive in a browser: https://drive.google.com, then …
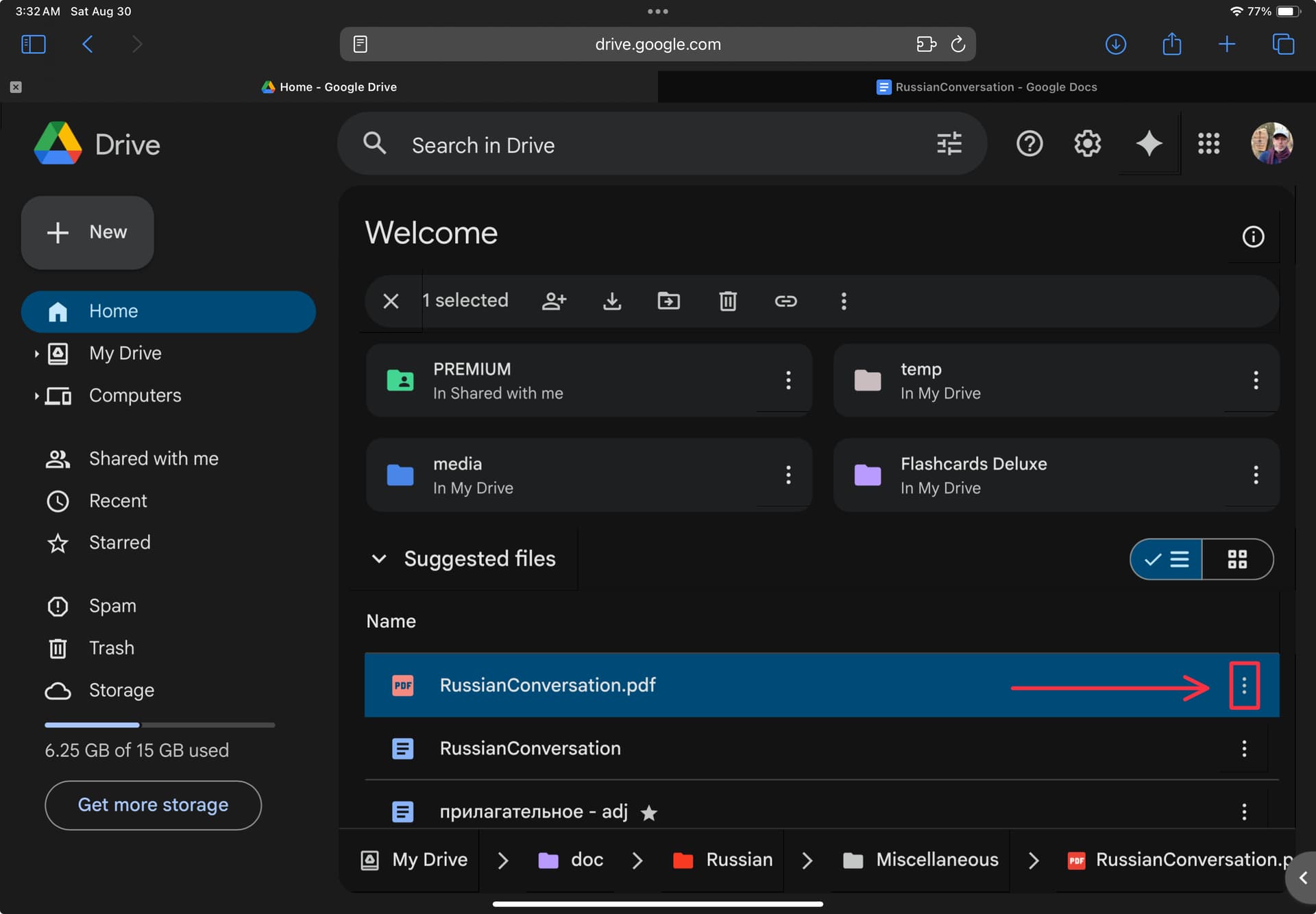
Upload a pdf file to Google Drive
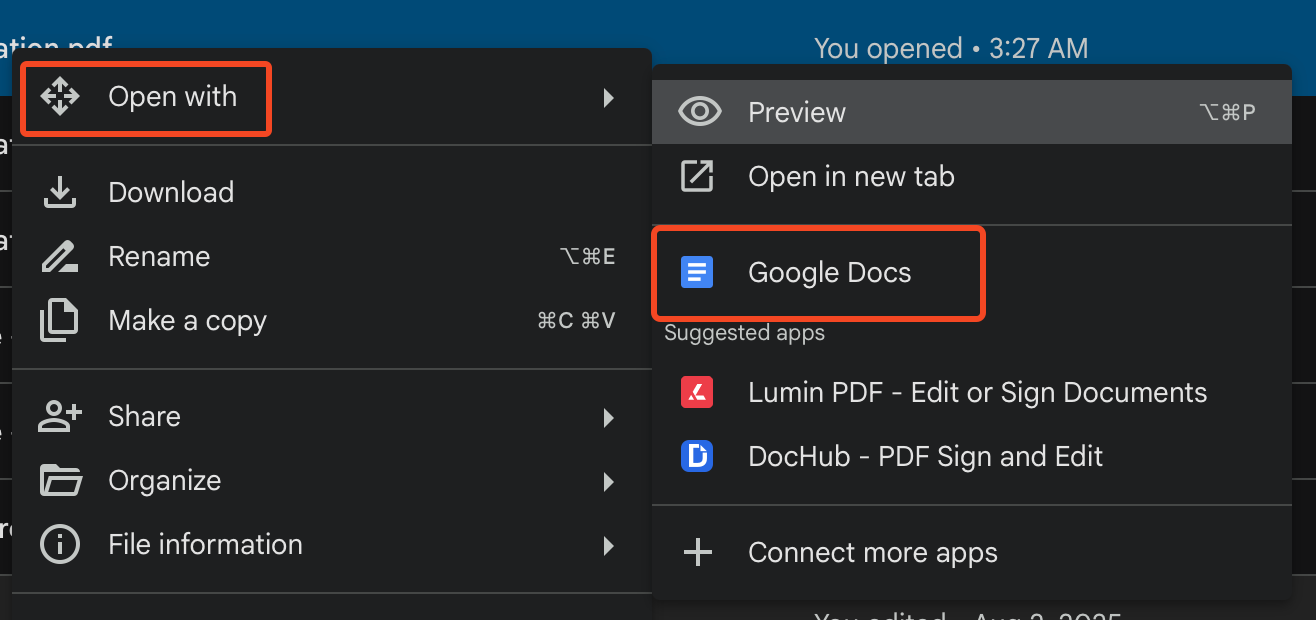
Right click (if using a mouse) on the file (on an iPad for example click on the three dots to the right of the file name as shown below).
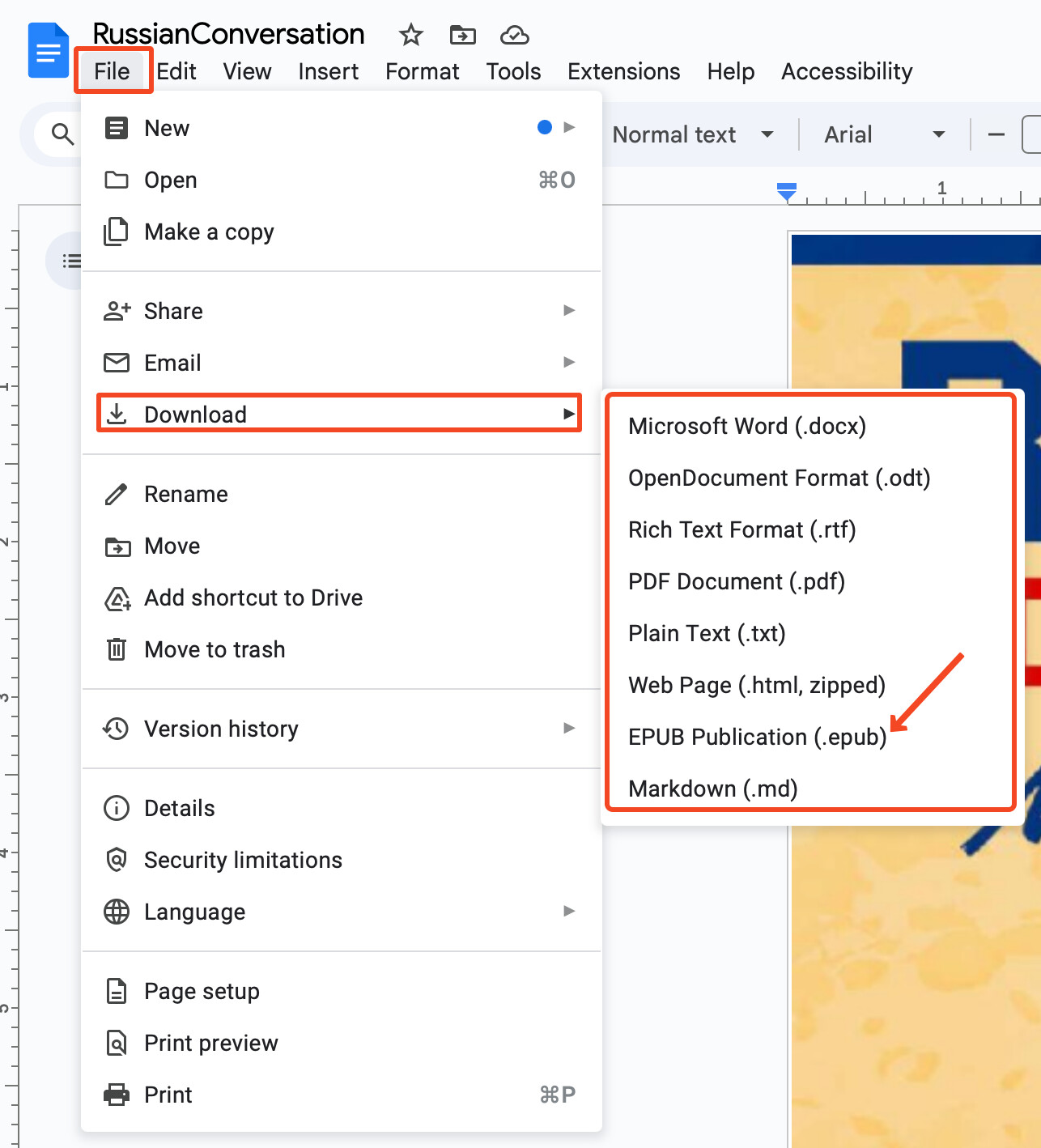
Select “Open With” then choose Google Docs and download in any of a number of formats. I choose epub to import into Readlang.